
our science
Data Overview
Presented here is a scatter plot showing temperature versus pH for all hotsprings sampled. Each dot on the graph represents an individual spring and is colour-coded according to the variable selected. The type of variable displayed is chosen by you from two options, chemical and taxonomic, as follows:
- On the left under Chemical Comparison, the scroll down menu lists all chemical species measured for each spring. Click on your preferred option and the dots will be colour-coded to that variable, ranging from yellow (low concentration) to red (high concentration). These values are in parts per million or ppm for all chemical species listed, except for carbon monoxide, hydrogen and methane which are in microMolar or μM. Black dots represent chemical results still pending.
- On the right under Taxonomy Comparison, microbial diversity can be displayed either at domain or phylum taxonomic level. The domain option is either Bacteria or Archaea, whereas the phylum option lists all known bacterial and archaeal phyla to date. Here, the dots are colour-coded to the percentage of the chosen taxonomic level found in each spring (yellow equals low percent or abundance, and red, high abundance).
With both chemical and taxonomic options, holding the cursor over a dot will reveal that spring's pH, temperature and variable value (either in ppm, μM or percent, depending on what you have chosen to display). Clicking on the dot will bring you to the feature page of that individual spring.
Chemical Comparison
Taxonomy Comparison

Coming Soon!
“Uniqueness Metric” Development
One of the outputs of this research programme is to investigate a way of determining the
resident microbial community “uniqueness”. To the best of our knowledge there are no
defined methodologies to categorise whether the microbial community within an ecosystem
is novel - macroecologists have been grappling over these ideas when it comes to flora and
fauna for years. For example, is a microbial ecosystem unique because it has a single (or
multiple) globally or nationally rare microbial species? Is it unique because its total microbial
 community make-up is rare? Or is it is rare because of the microbial community -
physicochemical environment interactions? In this project, we are exploring ways to
characterise the physicochemical and microbial diversity data generated by developing a
‘uniqueness metric’.
community make-up is rare? Or is it is rare because of the microbial community -
physicochemical environment interactions? In this project, we are exploring ways to
characterise the physicochemical and microbial diversity data generated by developing a
‘uniqueness metric’.
Our initial thoughts about developing a uniqueness metric is to consider the microbial community structures independent of the associated physicochemical conditions (not necessarily correct - but a reasonable first strategy). Things we are considering:
- Diversity measures
- The alpha-diversity of each sample - what are the dominant OTUs, what are the rare OTUs?
- The beta-diversity of each community - compare the community compositional dissimilarity within a geothermal system
- The relative importance of richness versus abundance - what is more valuable, a large number of evenly distributed OTUs or community made up of a small number of OTUs?
- Are these communities or microbial OTUs nationally and/or globally rare? And what is rarity? Is it a measure of phylogenetic dissimilarity from other species/communities? Or does it extend further and also include the relative abundance of these communities or OTUs in ecosystems?
None of these considerations takes into account the physicochemical conditions encountered by the microbial communities. Indeed some would even argue that the microbial community composition is dictated by the environmental conditions although this doesn’t take into consideration biogeography and microbial distribution between geothermal systems.
As a first pass at developing a uniqueness metric we processed all the OTUs generated from 162 sample sites across all sites through the microbial ecology software package Qiime using default settings. Weighted and un-weighted Unifrac indices for each sample site were generated and visualised on a hierarchical clustering UPGMA tree, along with nodal interactions networks and a Principle Coordinate analysis (PCoA) of the data overlayed with environmental data. The some of these visualisations are presented below (Caporaso et al. 2010).
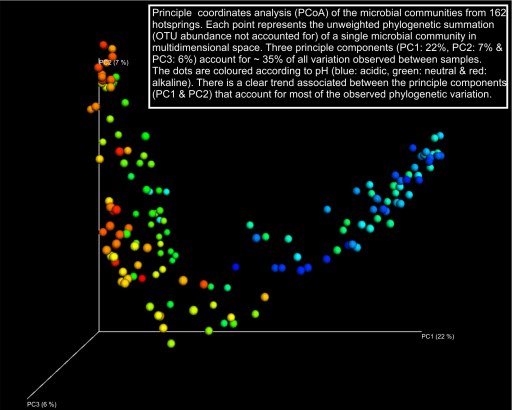
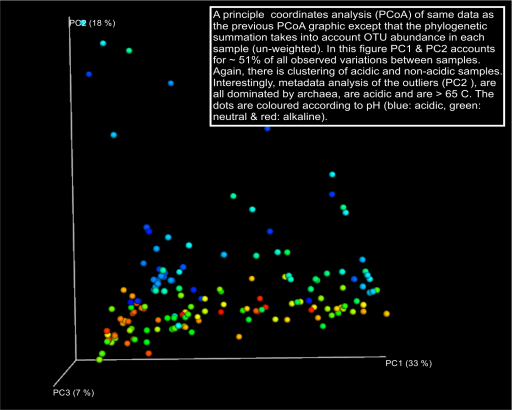
We will update this component of the Uniqueness Metric as our ideas develop. Please contact us if you have ideas you’d like to share with us.
References
Caporaso, J.G., Kuczynski, J., Stombaugh, J., Bittinger, K., Bushman, F.D., Costello, E.K., Fierer, N., Peña, A.G., Goodrich, J.K., Gordon, J.I., Huttley, G.A., Kelley, S.T., Knights, D., Koenig, J.E., Ley, R.E., Lozupone, C.A., McDonald, D., Muegge, B.D., Pirrung, M., Reeder, J., Sevinsky, J.R., Turnbaugh, P.J., Walters, W.A., Widmann, J., Yatsunenko, T., Zaneveld, J., and Knight, R. 2010. QIIME allows analysis of high-throughput community sequencing data. Nature Methods, 7(5), 335-336.

